

AI-generated content drifts into fantasy land more often than anyone who’s tried to fact-check a chatbot would like. Various studies report hallucination rates ranging from roughly 3% to 40% depending on the model and task, turning the promise of artificial intelligence into the peril of artificial nonsense. Improving this isn’t just a technical fix; it redefines trust in AI. This list cuts through the noise, revealing the core techniques that genuinely make AI smarter and more reliable for anyone tired of digital fabrications.
1. Retrieval-Augmented Generation (RAG)

Giving AI models a fact-checking lifeline before they speak.
AI chatbots sometimes generate incorrect information with the swagger of someone who definitely did not read the assignment. Retrieval-Augmented Generation, or RAG, cuts through this noise by giving large language models (LLMs) a real-time fact-check. This system combines an LLM with an external information retrieval component, such as a vector database. It ensures the model accesses up-to-date, private, or domain-specific data, directly reducing those embarrassing hallucinations.
RAG operates in four stages: data ingestion, query retrieval, prompt augmentation, and generation. This structured approach means the LLM first retrieves relevant documents, then augments its prompt with that context before crafting a response. Grounding answers in verifiable sources beats the alternative (AI recommending industrial glue for pizza toppings). It also significantly reduces the need for expensive model retraining whenever new information emerges, making your AI smarter without louder nonsense.
2. Vector Database (in RAG context)
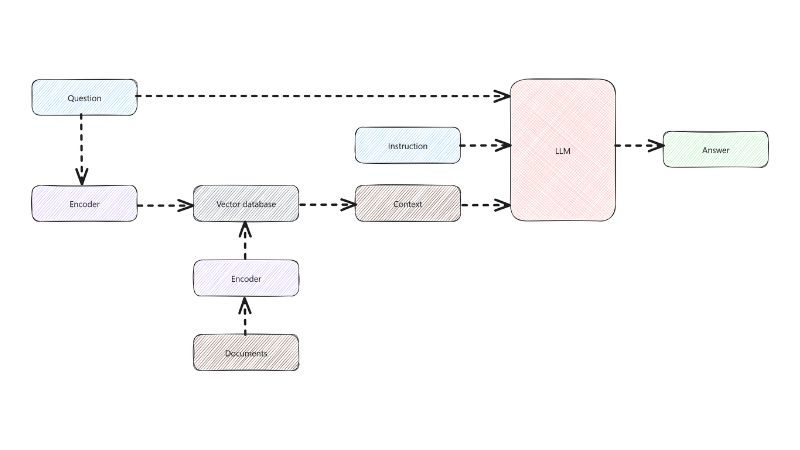
High-dimensional math that makes semantic search actually work.
High-dimensional numerical vectors form the bedrock of efficient information retrieval in advanced AI systems. These databases store data (text chunks, documents) as numerical embeddings, enabling true similarity search rather than simple keyword matching. Functioning as the content store in RAG systems, a retriever runs semantic searches over its index. This process acts like a well-trained librarian, instantly pinpointing intent beyond isolated words.
Optimized for nearest neighbor search, vector databases achieve low-latency retrieval across millions or billions of vectors. They commonly store chunked, embedded proprietary documents, ensuring LLMs ground responses in trusted sources. Legal professionals sifting through case files find exact precedents without an LLM’s confident guesswork. This precision extracts specific information, preventing the digital equivalent of an LLM going full chaos agent with made-up facts.
3. Model Size and Domain-Specific vs General-Purpose LLMs
Choosing the specialist over the generalist prevents costly AI mistakes.
General-purpose large language models boast broad, open-domain knowledge and often feature vast parameter counts. Their Achilles’ heel emerges in specialized niches where they may hallucinate. Domain-specific models step in like subject matter experts. These LLMs, potentially much smaller, are trained on concentrated data within a narrow field, leading to higher accuracy. Choosing a model fit for purpose reduces hallucinations and ensures precise, reliable information. This targeted approach means less time sifting through irrelevant or incorrect AI output, a real win for anyone tired of vague tech answers.
4. Chain-of-Thought Prompting (CoT)
Making AI show its work transforms guesswork into traceable logic.
When tackling a complex math problem where the intuitive first answer is subtly, frustratingly wrong, Chain-of-Thought (CoT) prompting provides a clear path. This technique instructs LLMs to generate intermediate reasoning steps before delivering a final answer. Research by Wei and colleagues showed it significantly improves performance on multi-step arithmetic, commonsense, and symbolic reasoning, particularly in models around 100 billion parameters.
This method boosts logical consistency and transparency, allowing anyone to trace the AI’s thought process. Consider a factory producing 240 widgets, with three times as many red as blue; CoT helps confirm the 60 blue widgets by detailing each calculation. The technique has limited effect on pure knowledge recall accuracy when underlying facts are wrong or missing, but showing the work reveals where reasoning breaks down.
5. Zero-Shot Chain-of-Thought Prompting

A simple phrase that unlocks step-by-step reasoning without examples.
Zero-shot Chain-of-Thought prompting offers a straightforward path to enhanced AI reasoning. This variant requires no examples; augment your prompt with a simple instruction such as “Let’s think step by step” to elicit a detailed reasoning chain. Research by Kojima and colleagues demonstrated this dramatically improves reasoning performance on some benchmarks, especially for math or logic problems, often yielding better results than direct-answer prompts.
The power lies in its straightforwardness: no meticulously curated examples are required. Transparency replaces blind trust, revealing the AI’s process. For practical use, prompt the model: “Calculate the final price for a $75 item after a 20% discount. Let’s think step by step.” The AI will walk through the multiplication, subtraction, and final answer instead of spitting out a number.
6. Few-Shot Chain-of-Thought Prompting

Teaching by example produces more accurate reasoning on complex tasks.
Few-Shot Chain-of-Thought Prompting supplies the LLM with several example question–answer pairs where the answers include explicit, step-by-step reasoning. This process effectively teaches the model the desired reasoning format, much like a meticulous law clerk demonstrating how to untangle a knotty clause. The LLM then imitates this demonstrated pattern on new questions, improving its performance significantly.
This technique often achieves higher accuracy for complex multi-step tasks compared to zero-shot CoT. It relies on carefully choosing representative examples, which can be combined with clustering methods to cover diverse question types. When prompted with a multi-clause contract, an output informed by these precise examples delivers a far more accurate and detailed breakdown, cutting through legalese like a seasoned litigator.
7. LLM Chaining (Multi-LLM Consensus / Self-Refine Patterns)
Multiple AI passes or models working together catch errors single calls miss.
LLM chaining tackles unreliable outputs by sequencing multiple LLM calls for revision, critique, or aggregation. One strategy involves a “revise and reflect” loop where an LLM first generates an answer, then critiques and improves its own output. This acts as an externalized reflection, much like re-reading your own email before hitting send, drastically boosting reliability compared to a single, one-shot response.
Another effective method is the “panel of experts” pattern. Here, the same query is sent to multiple LLMs, and a separate supervisor model synthesizes the best answer from their diverse inputs. This leverages wisdom-of-the-crowd effects, minimizing errors from any single model. These robust strategies create stronger, more trustworthy LLM outputs, moving beyond guesswork into something resembling peer review.
8. Mixture of Experts (MoE) Models
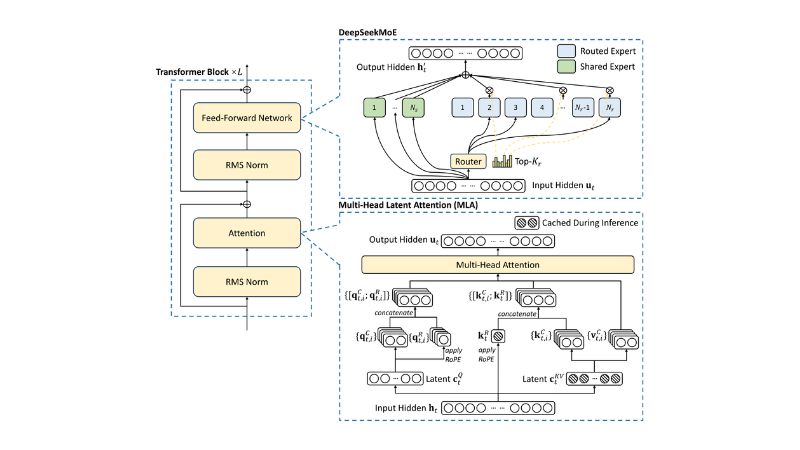
Specialized submodels handle what they do best, routing around weaknesses.
A Mixture of Experts (MoE) model brings targeted proficiency to complex AI tasks. This neural network uses multiple specialized submodels, or “experts,” each excelling in specific skills like math, code, or language fluency. A smart gating network routes incoming data to the most relevant subset. Only a fraction of experts activate per input, enabling massive parameter counts with comparable computational load.
By leveraging specialization and selective routing, MoE architectures can reduce errors on diverse tasks and increase accuracy across a broader range of patterns than a single monolithic model of similar compute budget. MoE operates not as separate brains but as a single, highly differentiated mind, delivering precise and efficient performance without general-purpose headaches.
9. Temperature Setting in Language Models

A simple dial that trades randomness for reliability or creativity for accuracy.
Temperature is a decoding parameter that controls the randomness of token sampling during text generation, acting as a crucial dial for an AI’s improvisational urges. A low temperature, near 0.0, produces deterministic outputs. It delivers factual, consistent, and reliable answers, ideal for science questions, Q&A, or tasks demanding precision over poetry.
Conversely, higher temperatures unleash diverse and creative outputs, useful for brainstorming or crafting unique song lyrics. This allows your AI to go full improv artist, delivering varied wording but increasing hallucination risk. Adjusting this common knob trades accuracy for originality. Align it precisely with your task’s requirements, or your chatbot might drop a new track instead of your quarterly report.
10. System Prompt (System Message / Instructions)
Hidden instructions that set guardrails and keep AI focused on its job.
A silent conductor often guides the performance of even the most verbose AI, influencing every response without user input. This “system prompt” is a persistent, usually hidden instruction provided to a conversational LLM. It sets global behavior, defining the AI’s role, style, safety constraints, and factual accuracy priorities. In architectures like ChatGPT-style systems, the system message is prepended to every conversation, and user prompts are interpreted in the context of these higher-priority instructions.
These instructions enforce crucial guardrails. They ensure the LLM refuses harmful requests, resists prompt injection, and maintains strict domain boundaries. They also define task-specific guidance, like “You are a helpful cybersecurity assistant,” keeping the model focused and reducing off-domain hallucinations. This subtle, behind-the-scenes direction ultimately shapes the AI’s trustworthiness and utility.
11. Reinforcement Learning from Human Feedback (RLHF)
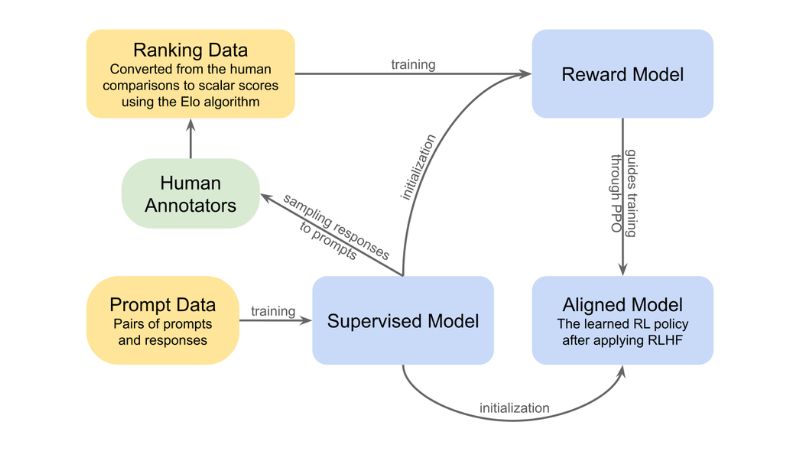
Human judgment trains AI to be helpful, harmless, and truthful over time.
The evolution of conversational AI often hinges on a crucial, often unseen, ingredient: direct human judgment. Reinforcement Learning from Human Feedback (RLHF) refines AI after supervised fine-tuning. Human annotators rate model outputs, and these preferences train a specialized reward model. This model then guides the LLM’s policy optimization, aligning it with human expectations on helpfulness, harmlessness, and truthfulness.
This iterative process makes AI more useful, reducing certain types of hallucinations and preventing digital nonsense. User thumbs-up or thumbs-down feedback provides ongoing RLHF data, acting as a real-time behavioral coach. RLHF has been central to the deployment of many modern chat-based LLMs, helping them follow instructions better, refuse unsafe requests, and reduce certain types of hallucinations, though it does not eliminate factual errors entirely. Human feedback forges more reliable digital assistants.























